阅读资料:
JPEG File Interchange Format Version 1.02
JEITA CP-3451 Exif Version 2.2
DIGITAL COMPRESSION AND CODING OF CONTINUOUS-TONE STILL IMAGES – REQUIREMENTS AND GUIDELINES
The JPEG Still Picture Compression Standard
JPEG 简易文档 V2.15 云风
libjpeg 6b
JPEG 原理详细实例分析及其在嵌入式 Linux 中的应用 http://www.ibm.com/developerworks/cn/linux/l-cn-jpeg/
JPEG文件编/解码详解 http://blog.csdn.net/lpt19832003/article/details/1713718
Huffman 编码压缩算法 http://coolshell.cn/articles/7459.html
A SIMPLE EXAMPLE OF HUFFMAN CODING ON A STRING http://nerdaholyc.com/a-simple-example-of-huffman-coding-on-a-string/
这是一篇自己学习JPEG的笔记,会不断完善,多数是别人的啦,少许自己理解,如有理解错误还请指出!
1、JPEG File格式分为两个部分:标记码和压缩数据
标记码由2个字节组成,以0xFF打头,后面的一个字节根据含义不同而定。每个标记码之前还可以加任意个0xFF来填充,他们没有什么意义,也就是说连续的多个0xFF被解释成一个0xFF。
2、
压缩算法是JPEG
色彩空间是YCbCr
APP0标记码是必须的
字节序都是大端
YCbCr的Cb和Cr一般都是有符号数,但是在JPEG当中都是无符号数,所以目前在JPEG当中的做法是RGB到YCbCr的转换是计算好Cb和Cr之后将其值增加128,再做后续的运算。
YCbCr到RGB的计算是先将Cb和Cr的值减去128后再来做转换。
假设一个数据单元,8 x 8的原始图像如下(转化为YCbCr之后的数据):
52 55 61 66 70 61 64 73
63 59 55 90 109 85 69 72
62 59 68 113 144 104 66 73
63 58 71 122 154 106 70 69
67 61 68 104 126 88 68 70
79 65 60 70 77 68 58 75
85 71 64 59 55 61 65 83
87 79 69 68 65 76 78 94
3、DCT(Discrete Cosine Transform)
在做FDCT(Forward DCT)变换的时候,Y,Cb和Cr的值都范围都是-128 ~ 127,所以都要被减去128。
适配范围,每个点都减去128:
-76 -73 -67 -62 -58 -67 -64 -55
-65 -69 -73 -38 -19 -43 -59 -56
-66 -69 -60 -15 16 -24 -62 -55
-65 -70 -57 -6 26 -22 -58 -59
-61 -67 -60 -24 -2 -40 -60 -58
-49 -63 -68 -58 -51 -60 -70 -53
-43 -57 -64 -69 -73 -67 -63 -45
-41 -49 -59 -60 -63 -52 -50 -34
使用FDCT并四舍五入取最接近的整数:
-415 -30 -61 27 56 -20 -2 0
4 -22 -61 10 13 -7 -9 5
-47 7 77 -25 -29 10 5 -6
-49 12 34 -15 -10 6 2 2
12 -7 -13 -4 -2 2 -3 3
-8 3 2 -6 -2 1 4 2
-1 0 0 -2 -1 -3 4 -1
0 0 -1 -4 -1 0 1 2
DC(Direct Current)/AC(Alternating Current)
什么是DC?什么是AC?
4、量化:
-26 -3 -6 2 2 -1 0 0
0 -2 -4 1 1 0 0 0
-3 1 5 -1 -1 0 0 0
-4 1 2 -1 0 0 0 0
1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
5、Zigzag
Zigzag的好处,在内存当中连续的点在图片上也是相邻的了,而且后面都是连续的0,可以继续使用RLE压缩。
于是就变成:
−26,−3,0,−3,−2,−6,2,−4,1,−4,1,1,5,1,2,−1,1,−1,2,0,0,0,0,0,−1,−1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
实际上我们的DC系数在编码的时候不会算到Zigzag里面,因为DC系数值比较大,并且相邻的两个数据单元的DC差值不会很大,所以JPEG使用了差分脉冲调制编码(DPCM)对相邻两个数据单元之间的DC系数进行差值编码,这是利用了两个数据单元之间的相关性。
对其他的63个AC系数会采用Zigzag编码。
6、RLE(Run Length Coding)
我们来用一个简单的例子来详细说明一下,假设以下是使用Zigzag编码过的63个AC系数数据:
57,45,0,0,0,0,23,0,-30,-16,0,0,1,0,0,0,0,0,0,0,..,0
可以表示为
(0,57) ; (0,45) ; (4,23) ; (1,-30) ; (0,-16) ; (2,1) ; EOB
EOB实际就是结束,也可以用(0,0)表示,如果最后面不是以0结束的就不需要
解释下这个含义,编码后的含义就是说在57之前有0个0,在45之前有0个0,在23之前有4个0,在-30之前有1个0,以此类推。
需要值得注意的是,我们后面还会对这样的数据使用Huffman压缩,但是该算法要求这个表示0的个数的值的位数是4bit,也就是说能保存的值的范围是0 ~ 15。
所以碰到连续大于15个0的情况的时候,我们会拆分(15,0) ; (3,2) ; … ; (15,0) ; (15,0) ; (1,4),用(15,0)表示连续的16个0,也就是表示:
19个0,2, … ,33个0,4。
7、Canonical Huffman Code
在做好这些工作之后,JPEG还会对数据进行压缩,利用Canonical Huffman Code编码,对出现频率更高的数据采用更短的码字来编码。
这里将数值按照位数分为了16组。
数值 组 实际保存值
0 0 -
-1,1 1 0,1
-3,-2,2,3 2 00,01,10,11
-7,-6,-5,-4,4,5,6,7 3 000,001,010,011,100,101,110,111
-15,..,-8,8,..,15 4 0000,..,0111,1000,..,1111
-31,..,-16,16,..,31 5 00000,..,01111,10000,..,11111
-63,..,-32,32,..,63 6 .
-127,..,-64,64,..,127 7 .
-255,..,-128,128,..,255 8 .
-511,..,-256,256,..,511 9 .
-1023,..,-512,512,..,1023 10 .
-2047,..,-1024,1024,..,2047 11 .
-4095,..,-2048,2048,..,4095 12 .
-8191,..,-4096,4096,..,8191 13 .
-16383,..,-8192,8192,..,16383 14 .
-32767,..,-16384,16384,..,32767 15 .
之前RLE之后的结果:
(0,57) ; (0,45) ; (4,23) ; (1,-30) ; (0,-16) ; (2,1) ; EOB
现在仅对后面的值进行变换,前面表示0的个数的值不动。
57是第6组的,实际保存值为111001,所以被编码为(6,111001)
45,同样的操作,编码为 (6,101101)
23 -> (5,10111)
-30 -> (5,00001)
-8 -> (4,0111)
1 -> (1,1)
前面的那串数字就变成了:
(0,6), 111001 ; (0,6), 101101 ; (4,5), 10111; (1,5), 00001; (0,4) , 0111 ; (2,1), 1 ; (0,0)
括号里的数值正好合成一个字节,后面被编码的数字表示范围是-32767 ~ 32767。
合成的字节里,高4位是前续0的个数,低4位描述了后面数字的位数。
接着变,下面的变化就需要去查找Huffman编码表了,这个是在压缩之前就应该构建好的,这个表是将0 ~ 255的8位定长数根据其出现的频率不同映射成为1 ~ 16位不定长数,频率大的小于8位,频率小的高于8位。这点很重要,当然这个表是如何构建出来的也很重要。
现在我们假设查表得知:
6 = (0,6) --- 111000 (注: 6 = 0 * 16 + 6 = 0x06)
69 = (4,5) --- 1111111110011001 (注: 69 = 4 * 16 + 5 = 0x45)
21 = (1,5) --- 11111110110
4 = (0,4) --- 1011
33 = (2,1) --- 11011
0 = EOB = (0,0) --- 1010
那么最终我们得到的AC系数按位流就如下:
111000 111001 111000 101101 1111111110011001 10111 11111110110 00001 1011 0111 11011 1 1010
好奇:看起来前面括号里用的编码(范围为0 ~ 255)和后面编码的数字范围为-32767 ~ 32767的来自不同的编码基础?这样不会混淆么?
前面的编码数据(也就是说之前组合起来的一字节的数据,高4位0的个数,低4位非0数据编码后所占的位数)可以根据Huffman表查询出来,这样我们就可以得到紧跟着的数据的位数,读取相应的数据,所以不会混淆。
8、DC编码
DC在每个数据单元之中只有一个,并且连续数据单元之间的DC有紧密的联系,所以JPEG当中就采用的差分脉冲调制编码(DPCM)。
相邻单元之间
Diff = DC(i) – DC(i-1)
所以
DC(i) = DC(i-1) + Diff
我们保存的DC都是和上一个DC的差值,所以DC(0)等于多少?云风说是0,我觉得不应该啊。
目前DC相关这部分需要进一步证实。
假设Diff为-511
就会被编码成(9, 000000000)
假设查表(一般在JPEG文件当中Y和C是不同的表,另外还分DC和AC,所以通常就有4个Huffman表)的9的Huffman编码为1111110,那么整个DC的二进制表示就为1111110 000000000。
将DC的数据流放到AC之前就可以组成完整的编码数据流。
1111110 000000000 111000 111001 111000 101101 1111111110011001 10111 11111110110 00001 1011 0111 11011 1 1010
9、疑问:
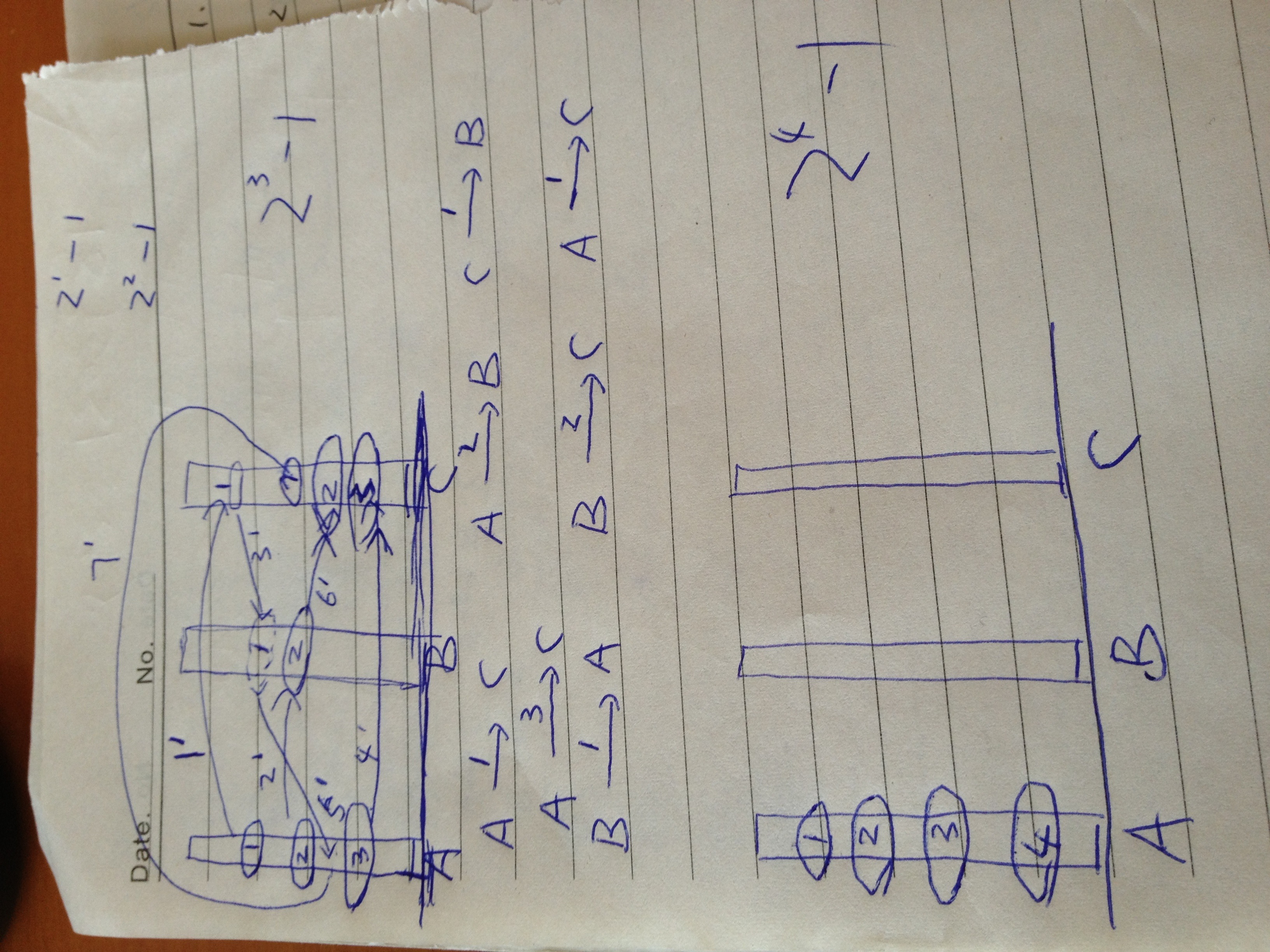
MCU和DU之间有关系吗?看起来这些压缩都是在DU当中进行的。
每个Y,Cb,Cr分量都要来这样压缩一次吗?还是3个分量一起压缩?或者说是可以根据采样的不同,将部分分量放在一起压缩,比如Cb和Cr一起压缩,Y单独压缩。
看起来Cb可以和Cr放在一起压缩。
UPDATE:
MCU可能有一个或者多个DU组成,压缩都是按DU来的,分量都是分开压缩的,一个MCU当中的Y,Cb,Cr都是分别压缩的,然后按MCU组装成字节流。
10、JFIF文件格式分析实例:
SOI(Start of Image)
APP0(JFIF application segment)
APP1(application reserved)
…
APP15
DQT(Define Quantization Table)
DHT(Difine Huffman Table)
SOF(Start of Frame)
SOS(Start of Scan)
EOI(End of Image)
IFD(Image File Directories)
标记的前2个字节为名字,也就是前面所说的标记码,接着的2个字节为该标记的所占空间大小(不包含标记名字的2个字节,但包含自己在内)
比如这一段数据
FF E0 00 10 4A 46 49 46 00 01 01 00 00 01 00 01 00 00
当中
0xFFE0为标记码,也就是APP0
0x0010为该标记所占大小,也就是16
后面跟的14个字节(“4A 46 49 46 00 01 01 00 00 01 00 01 00 00”)就是标记内容
根据SPEC的描述:
5字节为标识符,这里就是JFIF0
2字节为版本号(主版本和次版本各占1个字节),这里就是1.01
1字节为密度单位,0表示没有单位,1表示每英寸点数,2表示每厘米点数
2字节为水平像素密度,这里是1
2字节为垂直像素密度,这里是1
1字节为缩略图水平像素总数,这里是0
1字节为缩略图垂直像素总数,这里为0
如果没有缩略图,这两个缩略图相关的字段值都必须要为0,如果不为0就表示后面还有缩略图的RGB数据,大小是3字节的倍数。
对于DQT
FF DB 00 43 00 08 06 06 07 06 05 08 07 07 07 09 09 08 0A 0C 14 0D 0C 0B 0B 0C 19 12 13 0F 14 1D 1A 1F 1E 1D 1A 1C 1C 20 24 2E 27 20 22 2C 23 1C 1C 28 37 29 2C 30 31 34 34 34 1F 27 39 3D 38 32 3C 2E 33 34 32
FF DB 00 43 01 09 09 09 0C 0B 0C 18 0D 0D 18 32 21 1C 21 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
0xFFDB为标记码
0x0043为所占大小,也就是67(除去本身所占2字节,大小跟精度有关)
1个字节为QT信息,高4位为QT精度,低4位为QT号
还原成矩阵形式(Zigzag)
8 6 5 8 12 20 26 31
6 6 7 10 13 29 30 28
7 7 8 12 20 29 35 28
7 9 11 15 26 44 40 31
9 11 19 28 34 55 52 39
12 18 28 32 41 52 57 46
25 32 39 44 52 61 60 51
36 46 48 49 56 50 52 50
就是这样(JPEG 原理详细实例分析及其在嵌入式 Linux 中的应用这篇文章中应该画错了)
另外一个QT也是同样的方法可以还原。
对于SOF0这段数据
FF C0 00 11 08 00 95 00 E3 03 01 22 00 02 11 01 03 11 01
当中
0xFFC0表示SOF0
2个字节为长度,0x0011,即17
1个字节为数据样本的精度,这里是8位
2个字节表示图像的高度,这里是149
2个字节表示图像的宽度,这里是227
1个字节表示颜色分量数,JPEG都是YCrCb,即3
9个字节表示颜色分量信息,这里字节数是颜色分量数 multiply 3
因为分量信息中颜色分量ID占用1个字节,水平/垂直因子占用1个字节(高4位水平,低4位垂直),量化表占用1个字节
H 2:1:1
V 2:1:1
所以总体采样因子就是(2 * 2):(1 * 1):(1 * 1),即4:1:1
MCU宽是水平采样因子最大值 multiply 8(记该最大值为Hmax)
MCU高是垂直采样因子最大值 multiply 8(记该最大值为Vmax)
因此这里就是(Hmax * 8):(Vmax * 8) = 16:16
如果整幅图片的高度或者宽度不是MCU的整数倍,就需要padding,解码之后丢弃大于宽度或者高度部分的数据
在数据流当中,MCU是按从左到右,从上到下来排列的。
因为每个MCU由若干数据单元组成,而数据单元又必须是8:8的,所以MCU当中数据单元的个数就是4(Hmax * Vmax)
对于DHT,如下就有4个Huffman表
FF C4 00 1F 00 00 01 05 01 01 01 01 01 01 00 00 00 00 00 00 00 00 01 02 03 04 05 06 07 08 09 0A 0B
FF C4 00 B5 10 00 02 01 03 03 02 04 03 05 05 04 04 00 00 01 7D 01 02 03 00 04 11 05 12 21 31 41 06 13 51 61 07 22 71 14 32 81 91 A1 08 23 42 B1 C1 15 52 D1 F0 24 33 62 72 82 09 0A 16 17 18 19 1A 25 26 27 28 29 2A 34 35 36 37 38 39 3A 43 44 45 46 47 48 49 4A 53 54 55 56 57 58 59 5A 63 64 65 66 67 68 69 6A 73 74 75 76 77 78 79 7A 83 84 85 86 87 88 89 8A 92 93 94 95 96 97 98 99 9A A2 A3 A4 A5 A6 A7 A8 A9 AA B2 B3 B4 B5 B6 B7 B8 B9 BA C2 C3 C4 C5 C6 C7 C8 C9 CA D2 D3 D4 D5 D6 D7 D8 D9 DA E1 E2 E3 E4 E5 E6 E7 E8 E9 EA F1 F2 F3 F4 F5 F6 F7 F8 F9 FA
FF C4 00 1F 01 00 03 01 01 01 01 01 01 01 01 01 00 00 00 00 00 00 01 02 03 04 05 06 07 08 09 0A 0B
FF C4 00 B5 11 00 02 01 02 04 04 03 04 07 05 04 04 00 01 02 77 00 01 02 03 11 04 05 21 31 06 12 41 51 07 61 71 13 22 32 81 08 14 42 91 A1 B1 C1 09 23 33 52 F0 15 62 72 D1 0A 16 24 34 E1 25 F1 17 18 19 1A 26 27 28 29 2A 35 36 37 38 39 3A 43 44 45 46 47 48 49 4A 53 54 55 56 57 58 59 5A 63 64 65 66 67 68 69 6A 73 74 75 76 77 78 79 7A 82 83 84 85 86 87 88 89 8A 92 93 94 95 96 97 98 99 9A A2 A3 A4 A5 A6 A7 A8 A9 AA B2 B3 B4 B5 B6 B7 B8 B9 BA C2 C3 C4 C5 C6 C7 C8 C9 CA D2 D3 D4 D5 D6 D7 D8 D9 DA E2 E3 E4 E5 E6 E7 E8 E9 EA F2 F3 F4 F5 F6 F7 F8 F9 FA
2个字节为标记码
2个字节为长度
1个字节为类型和ID,高4位为类型,0为DC直流,1为AC交流;低4位为ID
也就是说这里有4个Huffman编码表,直流0,交流0,直流1,交流1
16个字节为码字的数量,以第一张表为例子,没有1位的码字,2位的码字1个,3位的码字5个,4到9位的码字各1个,没有9位以上的码字,所以一共是12个码字
剩下的12字节为编码内容(这12是根据码字数量得出的,1 + 5 + 1 + 1 + 1 + 1 + 1 + 1),
00 01 02 03 04 05 06 07 08 09 0A 0B
所以转换成二进制的话就应当如下:
位数 代码 码字
2 00 00
3 01/02/03/04/05 001/010/011/100/101
4 06 0110
5 07 00111
6 08 001000
7 09 0001001
8 0A 00001010
9 0B 000001011
UPDATE: 这上面的编码内容的理解应该是错误的,这是参照http://www.ibm.com/developerworks/cn/linux/l-cn-jpeg/来的。
实际应该是:
Length Code Codeword
2 00 00
3 01 010
3 02 011
3 03 100
3 04 101
3 05 110
4 06 1110
5 07 11110
6 08 111110
7 09 1111110
8 0A 11111110
9 0B 111111110
这个Huffman表是如何构建的,得好好研究,另外后面的压缩都会用到这个表的内容。
Huffman编码表的构建原理
第1个码字必须是0(根据其位数具体表现为0或00或000等等,以此类推)
下一个码字在前面一个的基础上加1,如果位数有增加,则加1之后补零到相应位数
值为00的为结束标志(EOB),编码或者解码时候注意其码字
EXIF通常是放在APP1当中
FF E1 66 59 …… FF D9
0xFFE1(2字节)就是APP1的Marker名字,0x6559(2字节)是该字段的长度,为26201,但是不包含TAG名字所占用的2个字节。也就是说后面的实际内容占用了26199个字节,直到0xFFD9,这就是EXIF的内容。为什么会有个0xFFD9呢?我们都知道0xFFD9是EOI,因为EXIF里面的缩略图实际上也是一个完整的JPEG图片,它也有SOI等等这一些Marker。
参见JEITA CP-3451 Exif Version 2.2的Figure 7 Structure of Exif file with compressed thumbnail
因为EXIF并不是JPEG必须的,所以你把这之间的内容整个都拿掉(用16进制编辑器很好做到,有兴趣的可以试试看),对图片也没有什么影响,只是少了所有EXIF的信息。
11、Linux下编译libjpeg
download source tree
uncompress it
cd to source tree folder
clean the source tree
$ ./configure --enable-shared --enable-static
Maybe it will complain this message
./configure: 1562: ./ltconfig: not found // Here
but it does not matter, so we do not care it.
$ make
if it complains ‘make: ./libtool: Command not found’
then fix your configure file from
LIBTOOL=”./libtool”
to
LIBTOOL=”libtool”
‘Cause under your current source tree, there is of course no file named libtool, so it can not exec that command, so replace it with the system-wide libtool. BUT the prerequisite thing is that you have installed libtool on your host machine.
Then compile it again, everything should be okay.
After completed, remember there will be a folder name ‘.libs’ generated under your source tree folder, this is a HIDDEN folder, everything you need just under it.
$ ./cjpeg testimg.bmp > hello.jpeg
a new compressed jpeg file is generated
$ ./djpeg -bmp testimg.jpg > hello.bmp
a new bmp file is generated
use your imagination to do anything.
Good luck!