这是一篇阅读笔记,直接点击图片可以查看清晰大图。
参考资料
The H.264 Advanced Video Compression Standard, Second Edition,以下简称THAVCS
Information technology – Coding of audio-visual objects – Part 10: Advanced Video Coding,以下简称SPEC
CodecVisa
JM
foreman_part_qcif.264 这个是foreman_part_qcif.yuv通过JM 8.6转换来的
http://blog.csdn.net/stpeace/article/details/8114826
简单的理解帧内预测就是利用该帧里面已经编码和重构好的块来编码数据,具体做法就是用当前块减去预测块,得到的数据再编码
比如:
编码好的块 B 预测块 P 当前块 C Delta = C - P P是根据B预测来的,Delta是最终进行编码的数据,也就是我们经常说的Residual
对于亮度分量,P一般是4 x 4的块或者16 x 16的宏块(8 x 8的只在high profile当中出现),对于细节比较丰富的地方使用4 x 4的块,对于比较平坦的地方使用16 x 16的块的(这样做的原因就是通常块分的越细就需要越多的位来存放这些块自身的信息,但预测的殘差会比较小;块分的越大,存放块本身信息所占用比较少的位,预测的时候殘差就会占用更多的位,所以这是一个权衡)。并且我们一般记作4 × 4 Luma Prediction和16 × 16 Luma Prediction。
4 × 4 Luma Prediction有9种预测模式,参见THAVCS书的Figure 6.10和Figure 6.11,名字就不一一列举了,这里有截图。

那这么多预测模式我们到底使用哪一个是如何决定的呢?这里就涉及到一个SAE(Sum of Absolute Errors),这个SAE表示预测的错误或者偏差,明显SAE越大越不准确,所以这里我们当然选择SAE最小的那个,至于SAE是如何算出来的,我们暂时不考虑。
16 × 16 Luma Prediction有4种预测模式,参见THAVCS书的Figure 6.13,截图如下,当然选用那种模式跟上面的方法一样,也是看SAE。
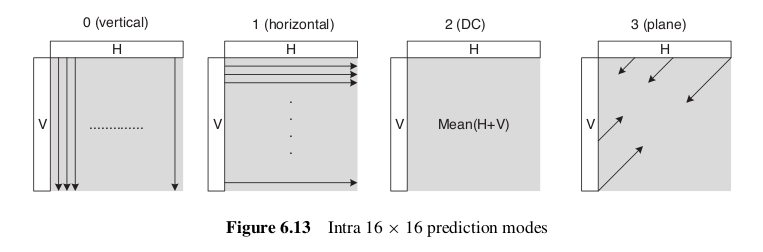

对于色度分量,P一般是8 x 8的块,记作8 × 8 Chroma Prediction。它也是有4种预测模式,跟16 × 16 Luma Prediction一样,只是模式的编号不一样,具体如下,DC(mode 0), Horizontal(mode 1),Vertical(mode 2)和Plane(mode 3)。
知道这些总体上的知识之后,我们来稍微深入看看具体的,这个时候就需要用到CodecVisa了。打开码流,可以看到MB(MacroBlock)信息如下,
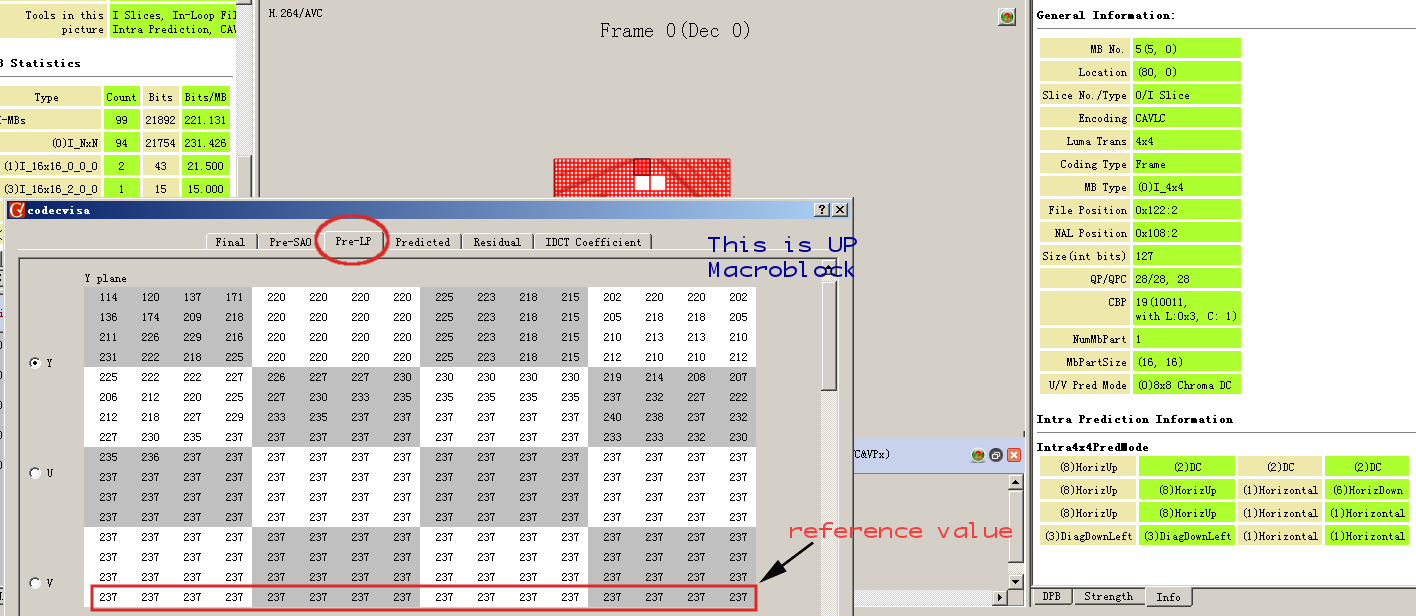
从MB统计信息(h.264-foreman-1st-frame-mb-statistics)来看,该Picture是I-Slice,一共有99个I-MBs,94个I_NxN类型,2个I_16x16_0_0_0类型,1个I_16x16_2_0_0类型,1个I_16x16_3_1_0类型以及1个I_16x16_2_0_1类型,具体这些类型的含义可以参见SPEC的Table 7-11 – Macroblock types for I slices。
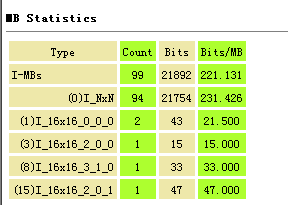
各个MB的分布情况如下,当然下图只能比较容易的区分出16 x 16的5个MB,

另外第一个MB的详细信息如下,
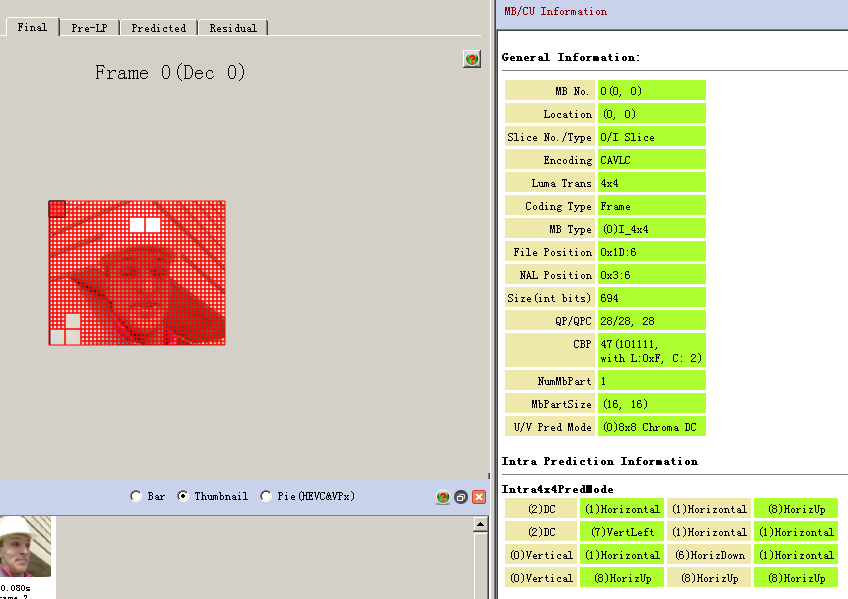
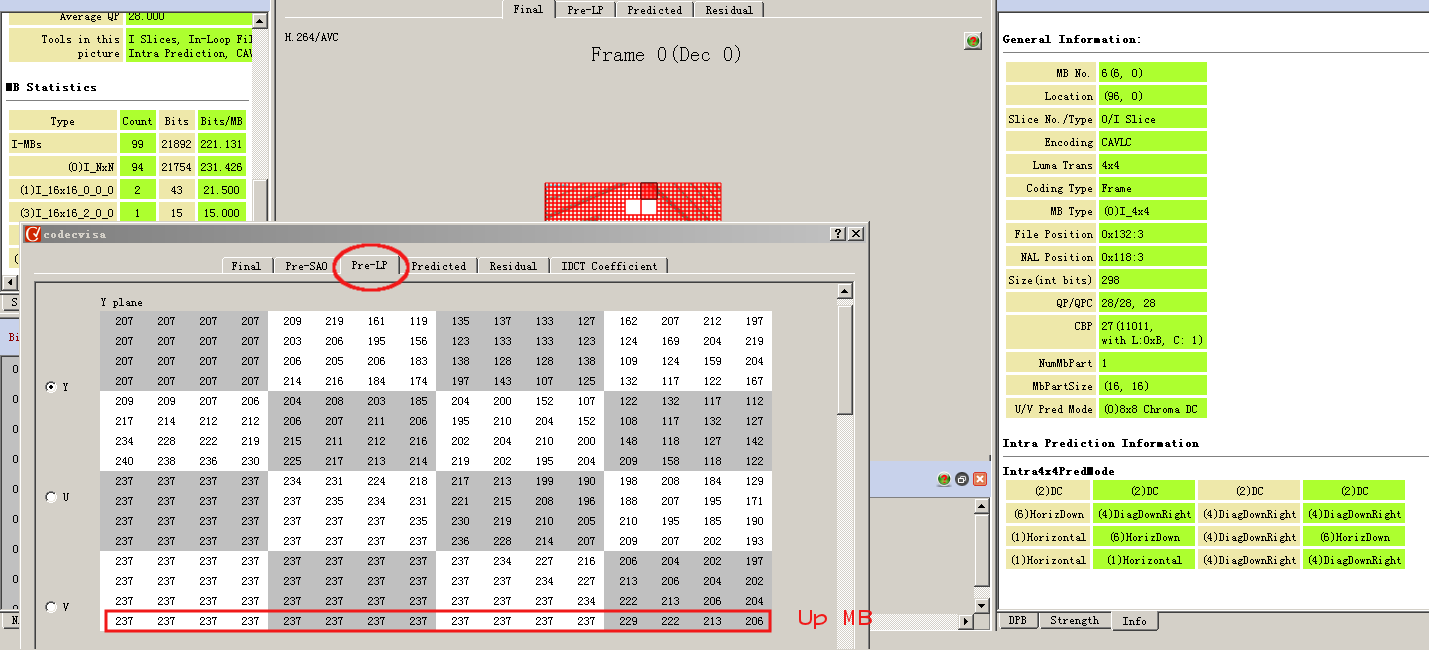
I_16x16_0_0_0表示预测模型是0(Vertical),而且我们知道这是Y分量,我们可以对照CodecVisa验证。通过h.264-foreman-1st-frame-i_16x16_0_0_0-mb我们可以看见这个MB的预测值都是237,而且因为它的预测模型是Vertical,所以我们可以推理出,该MB上面对应的位置的值应该也都是237,通过CodecVisa查看对应位置的数据截图如h.264-foreman-1st-frame-i_16x16_0_0_0-mb-up-mb,可以看出确实是237,这与我们说的Vertical模式正好吻合。至于实际值是236,这当然预测的值和实际值肯定是有误差的,所以这个误差-1通过Residual记录下来。
下面是预测值

I_16x16_2_0_0表示预测模型是2(DC),这也是Y分量,同理我们也可以验证。DC是Up的值和Left的值的均值,即((237 * 12 + 229 + 222 + 213 + 206) + (236 * 16)) / (16 * 2),约等于234,这里取整的误差我们认为这些误差是可以接受的,通过CodecVisa我们也可以观察出来,预测值确实为234。
Up和Left的MB如下

预测值为

另外比如4 x 4的Horizontal Up/Down这些要额外插值计算的预测原理也是如此,只不过稍微复杂点。
这里我们来简单分析下,首先是MB的划分,拆分成8 x 8,里面再拆分成4 x 4,处理的顺序就是先对第1个8 x 8块里面的4个4 x 4块按照光栅顺序处理,然后对第2个8 x 8块进行处理,如下图所示,

那么对某个具体的4 x 4块预测的时候就好办了,比如我们以Horizontal Up为例子,参照SPEC 8.3.1.2.9 Specification of Intra_4x4_Horizontal_Up prediction mode,截图如下,

这就是我们预测的公式,当中p[-1, y]就是我们用来预测的像素,如果没有的话,是不能完成这种模式的预测的。这个预测公式也很容易看懂,x和y就是你要预测的4 x 4块里面每个像素的坐标,所以它们范围只能是0至3。
另外下图我画了比较形象的图来说明,p[-1, y]就代表这里的I,J,K和L,同样图形的坐标里面的值是一样的,图形里面数字一样的表示是用同一个公式计算出来的(公式一样,代入值不一样,所以结果值不同,另外这种内部标记的我没有画完全,只是画出来一个来说明这种情况,就是坐标为[1, 0]和[1, 1]的两个位置),看图,

JM的代码也有比较直观的展示,
case HOR_UP_PRED:/* diagonal prediction -22.5 deg to horizontal plane */
if (!block_available_left)
printf ("warning: Intra_4x4_Horizontal_Up prediction mode not allowed at mb %d\n",img->current_mb_nr);
// 一个MB会被拆分成16个4 x 4的块(当然先拆分成4个8 x 8的块),一个4 x 4的块又会包含16个像素,就是这里
// zHU = x + 2 * y; // x = 0..3, y = 0..3
img->mpr[0+ioff][0+joff] = (P_I + P_J + 1) / 2; // (p[−1, y + (x >> 1)] + p[−1, y + (x >> 1) + 1] + 1) >> 1 代入 x = 0, y = 0
img->mpr[1+ioff][0+joff] = (P_I + 2*P_J + P_K + 2) / 4; // (p[−1, y + (x >> 1)] + 2 * p[−1, y + (x >> 1) + 1] + p[−1, y + (x >> 1) + 2] + 2) >> 2 // 代入 x = 1, y = 0 注意right shift
img->mpr[2+ioff][0+joff] =
img->mpr[0+ioff][1+joff] = (P_J + P_K + 1) / 2;
img->mpr[3+ioff][0+joff] =
img->mpr[1+ioff][1+joff] = (P_J + 2*P_K + P_L + 2) / 4;
img->mpr[2+ioff][1+joff] =
img->mpr[0+ioff][2+joff] = (P_K + P_L + 1) / 2;
img->mpr[3+ioff][1+joff] =
img->mpr[1+ioff][2+joff] = (P_K + 2*P_L + P_L + 2) / 4;
img->mpr[3+ioff][2+joff] =
img->mpr[1+ioff][3+joff] =
img->mpr[0+ioff][3+joff] =
img->mpr[2+ioff][2+joff] =
img->mpr[2+ioff][3+joff] =
img->mpr[3+ioff][3+joff] = P_L; // p[ −1, 3 ]
break;
这就是Horizontal Up预测,应该就有了比较透彻的理解。这照相机拍的图在这里显示的orientation不对,直接点过去看大图吧,大图是正确的。
THAVCS当中关于Loop filter的 描述。
A filter is applied to every decoded macroblock to reduce blocking distortion [iv]. The de-
blocking filter is applied after the inverse transform in the encoder before reconstructing and
storing the macroblock for future predictions and in the decoder before reconstructing and
displaying the macroblock.
Intra-coded macroblocks are filtered, but intra prediction (section 6.3) is carried out using unfiltered reconstructed
macroblocks to form the prediction.
CodecVisa软件中Pre-LP表示Loop filter动作之前的数据,IDCT Coefficient表示Inverse DCT Coefficient。
在JM的ldecod和lencod当中会有与预测相关的代码,详见block.c当中名字以intrapred打头的方法,各种预测模式的算法都有。